一、介绍
preometheus 报警由 Alertmanager 的独立工具进行管理的,它是一个可以集群化的独立报警管理工具。
我们需要在 Prometheus 上定义报警规则,这些规则将使用收集到的指标并在指定的阈值或标准上可以触发警报,然后将其推送到 Alertmanager 中,警报在 Alertmanager 上的 HTTP 端点上接收。收到警报后,Alertmanager 会处理报警并根据其标签进行路由处理,然后由 Alertmanager 发送到外部目的地通知,如邮件、钉钉、微信、短信等。
二、安装部署
1、二进制包部署
下载地址:https://prometheus.io/download/
[root@cp-3 ~]# tar -xf alertmanager-0.22.2.linux-amd64.tar.gz -C /usr/local/
[root@cp-3 ~]# mv /usr/local/alertmanager-0.22.2.linux-amd64 /usr/local/alertmanager
[root@cp-3 ~]# ln -s /usr/local/alertmanager/alertmanager /usr/local/bin/alertmanager
[root@cp-3 ~]# ln -s /usr/local/alertmanager/amtool /usr/local/bin/amtool
[root@cp-3 ~]# alertmanager --version
alertmanager, version 0.22.2 (branch: HEAD, revision: 44f8adc06af5101ad64bd8b9c8b18273f2922051)
build user: root@b595c7f32520
build date: 20210602-07:50:37
go version: go1.16.4
platform: linux/amd64使用 systemd 管理:
[root@cp-3 ~]# vim /lib/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
After=network.target
After=syslog.target
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
[Install]
WantedBy=multi-user.target
[root@cp-3 ~]# systemctl daemon-reload
[root@cp-3 ~]# systemctl restart alertmanager
[root@cp-3 ~]# netstat -ntlp | grep alertmanager
tcp6 0 0 :::9093 :::* LISTEN 7394/alertmanager
tcp6 0 0 :::9094 :::* LISTEN 7394/alertmanager 此时可以通过 ip:9093 去访问 web 界面。
2、docker部署
docker run -d -p 9093:9093 --restart=always --name alertmanager prom/alertmanager
三、配置文件
默认配置文件:
[root@cp-3 ~]# cat /usr/local/alertmanager/alertmanager.yml
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']解读:
只是一小部分,建议阅读官方文档:https://prometheus.io/docs/alerting/latest/configuration)
route: # route用来设置报警的分发策略
group_by: ['alertname'] # 根据 Prometheus 的标签对报警分组。例如alertname、instance。
group_wait: 30s # 当收到报警时,如果同组内,30秒内出现相同报警,则会合并为一条发送一起发出去
group_interval: 5m # 同组中发送报警的间隔时间。即在发送添加到已发送初始通知的组中的新警报的通知之前要等待多长时间
repeat_interval: 1h # 重复报警的间隔时间。即如果报警没有解决,会在多久再发。
receiver: 'web.hook' # 设置默认接收人
receivers: # 定义接收者,将告警发送给谁。
- name: 'web.hook' # 接收者的唯一名称。
webhook_configs: # 通知方式
- url: 'http://127.0.0.1:5001/' # webhook地址
inhibit_rules: # 报警抑制
- source_match: # 源警报
severity: 'critical' # 报警级别为 critical
target_match: # 目标警报
severity: 'warning' # 报警级别为 warning
equal: ['alertname', 'dev', 'instance'] # 源警报和目标警报中必须具有相等值的标签才能使抑制生效。注:
inhibit_rules 这部分意思为:
在alertname、dev、instance 三个标签的值相同情况下,critaical 的报警会抑制 warning 级别的报警信息。
group_by、group_wait、group_wait、repeat_interval 详解:
1、group_by:
这个选项控制着 Alertmanager 分组报警的方式。
默认情况下所有报警都组合在一起,但如果我们指定了 group_by 和 标签,这它会按指定的标签分组。
例如,
group_by: ['alertname', 'instance'],表示不同实例不同报警将会分成不同组。
group_by: ['alertname'],表示按报警名称分,相同报警会分到一个组里。
这样的话,多台主机报相同的报警,会分到一个组里,然后你收到的报警通知可能一条包含了好几个主机。
其实这样不能很利于观测,建议分组分细点,按报警名称和实例分就挺好的
2、group_wait:
当收到报警时,不立即发出,等待此选项设定的时间,看在时间到之前是否还会收到同组的其它报警
如果有收到,就会合并为一条一起发出去
3、group_wait:
在发出报警后,如果收到该分组的下一次评估的新报警,那么将等待此选项设定的时间再发送新报警。
4、repeat_interval:
此选项适用单个报警,即重新发送相同报警的等待时间,如果这个时间段,报警还存在没解决就会再次发送邮件报警:
[root@cp-3 ~]# vim /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m # 在接下来的这个时间内,如果没有此报警信息触发,才发送报警解除消息。
smtp_smarthost: 'smtp.163.com:465' # smtp 地址
smtp_from: 'xxx@163.com' # 发件人邮箱地址
smtp_auth_username: 'xxx@163.com' # 发件人的登陆用户名,默认和发件人邮箱一致
smtp_auth_password: 'xxxxx' # 邮箱客户端授权码
smtp_require_tls: false # 是否需要tls协议。默认是true
route:
group_by: ['alertname']
group_wait: 0s
group_interval: 1s
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'xxx@163.com' # 收件人邮箱地址
send_resolved: true # 当报警解除时是否发送邮件通知,默认为false
[root@cp-3 ~]# systemctl restart alertmanager
四、报警规则
官方文档:https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
规则配置模板:https://awesome-prometheus-alerts.grep.to/rules
Alertmanager 配置好后,我们需要到 Prometheus 服务器上,配置Alertmanager的地址和报警规则文件位置。
[root@cp-3 ~]# vim /usr/local/prometheus/prometheus.yml
......
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093
rule_files:
- "rules/test.yml"
......报警规则:
[root@cp-3 ~]# mkdir /usr/local/prometheus/rules
[root@cp-3 ~]# cat /usr/local/prometheus/rules/test.yaml
groups:
- name: example
rules:
- alert: 系统平均负载过高
expr: node_load1 > on (instance) count (node_cpu_seconds_total{mode="system"}) by (instance)
for: 30s
labels:
severity: warning
annotations:
summary: "主机 {{ $labels.instance }} 的系统平均负载过高"
description: "{{ $labels.instance }} 主机系统平均负载过高,当前平均负载:{{ $value }}"解读:
groups:
- name:
rules:
- alert: # 报警名称
expr: # 要计算的PromQL表达式
for: # 告警持续时间,超过这个时间才会推送给 Alertmanager
labels: # 指定要附加到警报中的标签,冲突标签将被覆盖。标签值可以被模板化。
severity: # 报警等级标签(自定义的)
annotations: # 添加到每个警报的注释,例如警报描述或运行手册链接。注释值可以被模板化。
summary: # 概况(自定义的)
description: # 描述(自定义的)
注:
$labels # 此变量保存警报实例的标签键/值对。用法:{{ $labels.<labelname> }}
$value # 变量保存警报实例的评估值。用法:{{ $value }}模拟平均负载过高:
[root@cp-1 ~]# stress -c 10
stress: info: [15495] dispatching hogs: 10 cpu, 0 io, 0 vm, 0 hdd在 prometheus web界面的 alert 可以看到报警:
• Inactive:表示正常。
• Pending:表示报警还没有发送至 Alertmanager。
• Firing:表示 prometheus 已经将报警发给 Alertmanager。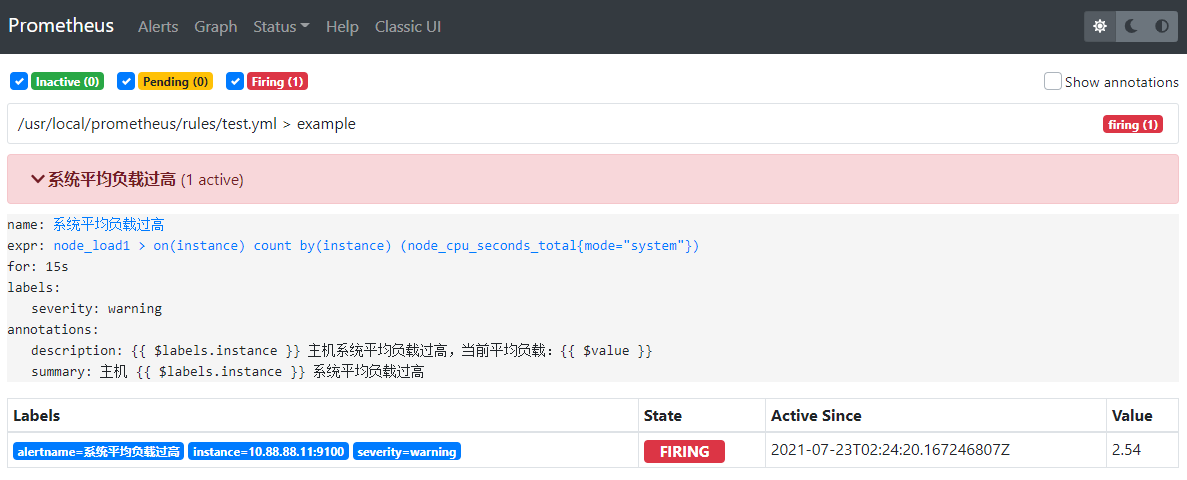
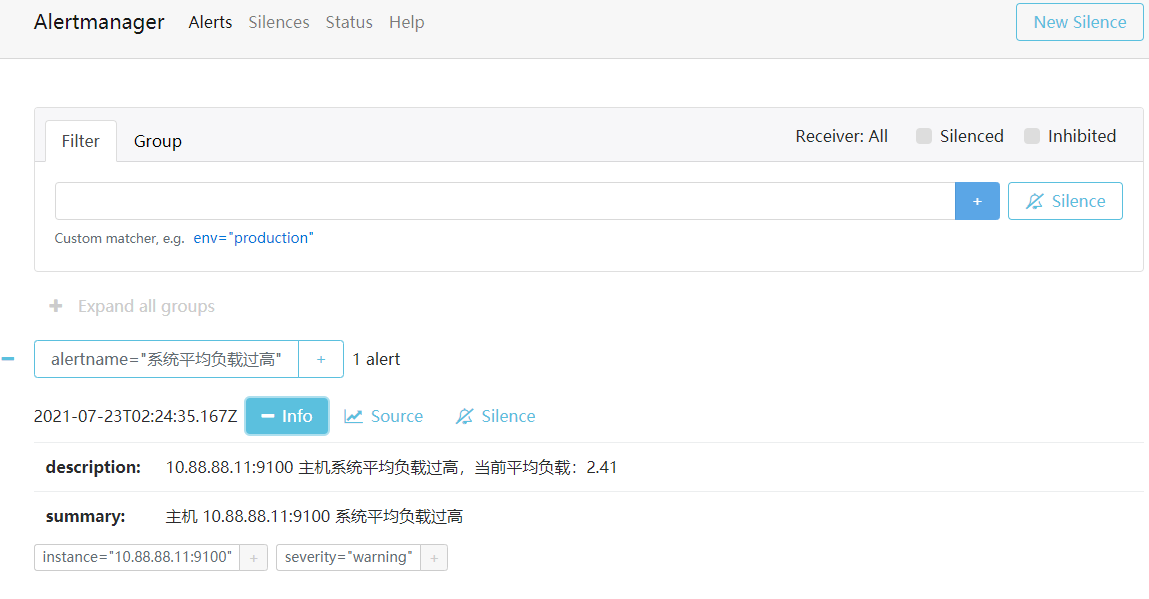
alertmanager web界面:
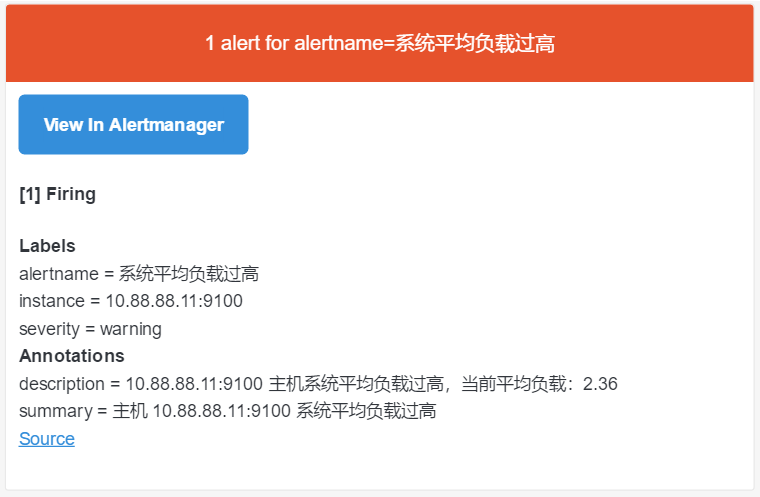
邮件报警通知:
五、模板
官方文档:https://prometheus.io/docs/alerting/latest/notifications/
通过上面的图,我们可以看到发送的邮件格式并不是很友好。其实在 Alertmanager 里,发送给接收者的通知是通过模板构建的。Alertmanager 带有默认模板,但它们也可以自定义。
我们自定义下电子邮件通知模板(go):
[root@cp-3 ~]# mkdir /usr/local/alertmanager/tmpl
[root@cp-3 ~]# vim /usr/local/alertmanager/tmpl/email.tmpl
#{{ define "email.from" }}xxxx@163.com{{ end }}
#{{ define "email.to" }}xxxx@163.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
===========================<br>
故障主机: {{ .Labels.instance }} <br>
报警级别: {{ .Labels.severity }} <br>
报警类型: {{ .Labels.alertname }} <br>
报警概述: {{ .Annotations.summary }} <br>
报警警详情: {{ .Annotations.description }} <br>
触发时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
===========================<br>
{{ end }}
{{ end }}
注:
1、email.from 和 email.to 是模板中自定义的变量,可以在 alertmanger 中引用。
2、email.to.html 是电子邮件通知的 HTML 正文。
3、{{ range .Alerts }} 是个循环语法,用于循环获取匹配的 Alerts 数组的信息。
4、开始触发时间为{{ .StartsAt }},但是通知的时间为UTC时间,改成上面这样即加8个小时就转变成CST时间。
注意应该使用"2006-01-02 15:04:05"这个时间,这里定义的时间为 go 语言的诞生时间,切记不能乱填。修改 Alertmanager 配置文件:
[root@cp-3 ~]# vim /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'xxxx@163.com'
smtp_auth_username: 'xxxx@163.com'
smtp_auth_password: 'xxxx'
smtp_require_tls: false
templates:
- /usr/local/alertmanager/tmpl/email.tmpl
route:
group_by: ['alertname', 'instance']
group_wait: 0s
group_interval: 1s
repeat_interval: 1h
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: 'xxxx@163.com'
html: '{{ template "email.to.html" . }}'
send_resolved: true再次模拟平均负载过高,再看报警邮件:

参考:
《Prometheus监控实战》
https://prometheus.io/docs
https://blog.csdn.net/aixiaoyang168/article/details/98474494