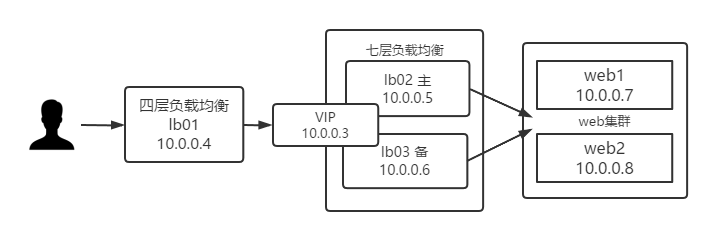
一、架构
二、基础概念
高可用,通俗的来说就是一台服务器宕机了,另一台马上接替,对于用户而言毫无感知的。专业的来说,就是尽可能减少服务的宕机时间。
keepalived作为这么一种高可用解决方案的软件,主要就是通过VRRP协议(虚拟路由器冗余协议)来实现高可用功能的,VRRP协议的主要目的就是为了解决路由单点故障问题的。
这么说keepalived其实就是将一组服务器组成一个热备组,这个组通过共享一个虚拟IP地址和MAC地址,来维护一个虚拟路由器。在任一时刻,该组中只有一个服务器是活跃的,这个虚拟IP也是处在活跃服务器上,其他处于备用模式。如果活跃服务器发生故障,那么这个虚拟IP会立刻漂移到备用服务器,备用服务器将会立刻接替其工作,这个接替对于访问的用户来说无感知的,因为虚拟IP是始终没有改变,所以仍能保持连接,不受故障影响。
keepalived是利用优先级来决定那个服务器成为活跃服务器,那个服务器的优先级高,则那个为活跃服务器。如果活跃服务器发生故障,备用服务器没有收到活跃服务器发出的VRRP 广播报文,则备用服务器就会成为新的活跃服务器。
三、配置keepalived服实现高可用
环境搭建:一台nginx四层负载均衡,两台nginx七层负载均衡,两个后端web节点,都提前部署好,这里不再赘述如何搭建。
(1)抢占模式
[root@lb02 ~]# yum install -y keepalived
[root@lb02 ~]# vim /etc/keepalived/keepalived.conf
global_defs { # 全局配置段
router_id lb02 # 路由标识,同一个局域网内唯一的。
}
vrrp_instance VI_1 { # VRRP协议配置端,这里定义一个名为VI_1的VRRP实例,用于配置一个VRRP服务。
state MASTER # 当前实例VI_1的角色状态,这个状态分MASTER和BACKUP两种状态。
interface ens33 # 绑定的对外提供服务的网络接口,虚拟机IP会配置到这个网卡上。
virtual_router_id 50 # 虚拟路由标识,同一个VRRP实例使用相同的唯一标识。
priority 100 # 优先级
advert_int 1 # 发送VRRP广播报文的时间间隔,单位为秒。
authentication { # 验证相关
auth_type PASS # 验证类型为密码,类型主要有PASS和AH两种。
auth_pass 0000 # 验证密码,其为明文,同一VRRP实例MASTER与BACKUP使用相同的密码才能正常通信。
}
virtual_ipaddress { #虚拟IP地址,即VIP
10.0.0.3
}
}
[root@lb03 ~]# yum install -y keepalived
[root@lb03 ~]# vim /etc/keepalived/keepalived.conf
global_defs {
router_id lb03
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 50
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 0000
}
virtual_ipaddress {
10.0.0.3
}
}测试:
[root@lb02 ~]# systemctl start keepalived //我们启动keepalived主节点
[root@lb02 ~]# ip a show ens33 //可以发现在ens33网卡下,多了一个VIP地址
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:72:d9:a3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::3bc6:290a:7d47:706/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@lb03 ~]# systemctl start keepalived //我们启动keepalived备节点
[root@lb03 ~]# ip a show ens33 //没有变化
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:27:27:71 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::aef:b68a:d2e7:4e3f/64 scope link noprefixroute
valid_lft forever preferred_lft forever此时我们模拟lb02服务器宕机,可以发现VIP立即从lb02服务器漂移到了lb03服务器上。
[root@lb02 ~]# systemctl stop keepalived
[root@lb02 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:72:d9:a3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::3bc6:290a:7d47:706/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@lb03 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:27:27:71 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::aef:b68a:d2e7:4e3f/64 scope link noprefixroute
valid_lft forever preferred_lft forever
(2)非抢占模式
通过上面我们可以发现,当主节点重新恢复正常,那么因为优先级会抢占VIP,VIP又会重新漂移到主节点,这样就发生了两次VIP地址漂移,其中第二次其实是不必要的VIP地址漂移。
为了避免这个情况,我们可以配置非抢占模式,即主节点故障,备节点接管,但主节点恢复了不会抢占VIP,除非备节点故障,主节点才会再次接管VIP。
配置非抢占模式主要有两个点:一是两个节点的状态都必须配置为BACKUP;二就是两个节点都在vrrp_instance中添加nopreempt参数即可。
[root@lb02 ~]# vim /etc/keepalived/keepalived.conf //修改添加以下参数
...
vrrp_instance VI_1 {
state BACKUP
nopreempt
...
}
[root@lb02 ~]# systemctl restart keepalived
[root@lb03 ~]# vim /etc/keepalived/keepalived.conf //修改添加以下参数
... ...
vrrp_instance VI_1 {
state BACKUP
nopreempt
......
}
[root@lb03 ~]# systemctl restart keepalived测试:模拟lb02宕机,可以发现VIP立即从lb02漂移到了lb03上。重新恢复lb02服务,发现VIP没有发生漂移,还在lb03上。
[root@lb02 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:72:d9:a3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::3bc6:290a:7d47:706/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@lb02 ~]# systemctl stop keepalived
[root@lb03 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:27:27:71 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::aef:b68a:d2e7:4e3f/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@lb02 ~]# systemctl restart keepalived
[root@lb02 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:72:d9:a3 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.5/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::3bc6:290a:7d47:706/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@lb03 ~]# ip a show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:27:27:71 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.6/24 brd 10.0.0.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 10.0.0.3/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::aef:b68a:d2e7:4e3f/64 scope link noprefixroute
valid_lft forever preferred_lft forever
四、扩展
(1)定义keepalived服务日志路径
keepalived服务日志默认会记录在/var/log/message下,观测起来不直观。
[root@lb02 ~]# vim /etc/sysconfig/keepalived //参数含义,配置文件中有解释
KEEPALIVED_OPTIONS="-D -d -S 0"
[root@lb02 ~]# vim /etc/rsyslog.conf // 配置rsyslog,定义服务日志存放路径
local0.* /var/log/keepalived.log
[root@lb02 ~]# systemctl restart keepalived rsyslog
[root@lb02 ~]# tailf /var/log/keepalived.log
...
Sep 9 07:02:19 lb02 Keepalived_vrrp[7619]: VRRP_Instance(VI_1) Sending/queueing gratuitous ARPs on ens33 for 10.0.0.3
Sep 9 07:02:19 lb02 Keepalived_vrrp[7619]: Sending gratuitous ARP on ens33 for 10.0.0.3
Sep 9 07:02:19 lb02 Keepalived_vrrp[7619]: Sending gratuitous ARP on ens33 for 10.0.0.3
...
(2)地址漂移问题
我们有没有想过VIP是什么时候才会漂移呢,一是 keepalived服务停止了,二就是服务器出问题了关机或者重启了。
那么问题来了,作为提供负载均衡的nginx服务如果出现故障了,而VIP却没有漂移,这就会导致网站服务访问失败。所以我们就需要编写一个脚本,用来探测Nginx是否存活,如果不存活则尝试启动,如果还没有存活,则强制停止keepalived服务,让VIP地址漂移。
#!/bin/bash
# 检测nginx进程是否存在,-C按名称匹配进程,--no-headers不显示列名。
nginx_pid=$(ps -C nginx --no-headers|wc -l)
# 判断Nginx是否存活,如果不存活则尝试启动Nginx。
if [ $nginx_pid -eq 0 ];then
systemctl start nginx
sleep 2
# 等待2秒后再次获取一次Nginx状态。
nginx_pid=$(ps -C nginx --no-header|wc -l)
# 再次进行判断, 如果Nginx还不存活则停止Keepalived服务,让地址进行漂移。
if [ $nginx_pid -eq 0 ];then
systemctl stop keepalived
fi
fikeepalived调用脚本
[root@lb02 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
router_id lb02
}
vrrp_script check_web { #定义脚本路径,定义脚本多久执行一次,定义名称check_web
script "/root/check.sh"
interval 5
}
vrrp_instance VI_1 {
state BACKUP
nopreempt
interface ens33
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 0000
}
virtual_ipaddress {
10.0.0.3
}
track_script { #调用脚本
check_web
}
}测试:
[root@lb02 ~]# systemctl stop nginx
[root@lb02 ~]# netstat -ntlp | grep nginx
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6890/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6976/master
tcp6 0 0 :::22 :::* LISTEN 6890/sshd
tcp6 0 0 ::1:25 :::* LISTEN 6976/master
[root@lb02 ~]# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 8064/nginx: master
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 6890/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 6976/master
tcp6 0 0 :::22 :::* LISTEN 6890/sshd
tcp6 0 0 ::1:25 :::* LISTEN 6976/master
(3)脑裂问题
当两个节点同时认为自己是唯一处于活动状态的时候,从而出现了VIP抢占,双方都在抢占资源的情况下,称为脑裂。
出现脑裂问题原因,主要就是VRRP广播报文因为某些原因导致发送或者接收问题(例如网络原因、防火墙原因等),导致双方接收不到报文,都认为对方故障,自身是唯一存活的,从而出现脑裂。